0x1 前言
最近分析两个apk,将后缀改为zip后,解压提示需要密码:

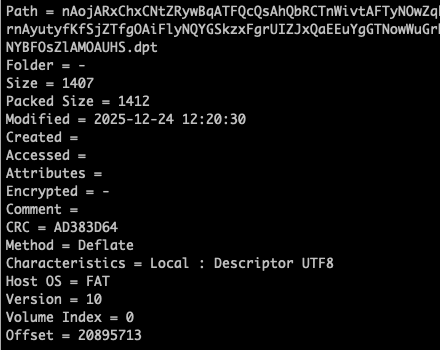
7z l -slt *.zip可以查看zip包内文件加密情况,大部分文件都如下图未标记加密:
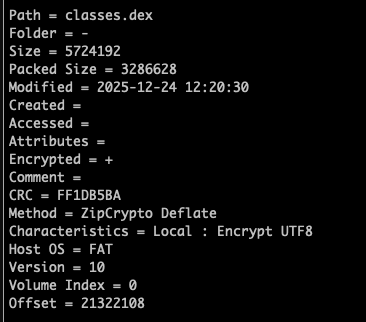
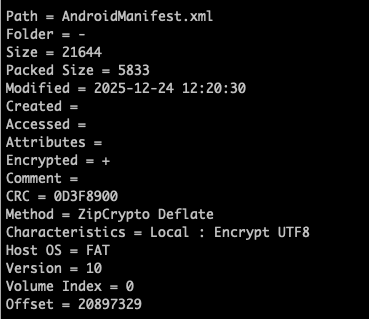
但classes.dex、AndroidManifest.xml等关键文件标记使用ZipCrypot Deflate加密方式:
但apk实际却可以被android模拟器直接安装,所以应该是采用了压缩包伪加密:
0x2 ZipCenOp
ZipCenOp是一个进行伪加密/解密的java工具,项目地址:https://github.com/442048209as/ZipCenOp
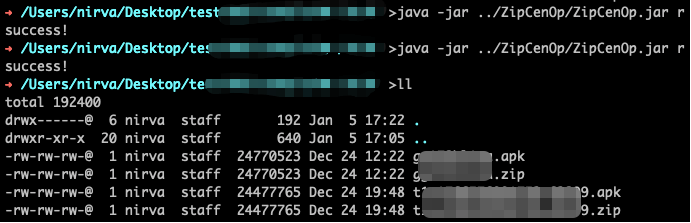
使用ZipCenOp去除伪加密,但执行后文件无变化,所以决定自己分析一下写个脚本解决这个问题:
java -jar ../ZipCenOp/ZipCenOp.jar r **.zip
success!
0x3 伪加密原理
在 ZIP 文件里,每个条目(ZipInfo)都有一个 flag_bits通用标志位(general purpose bit flag),通常 16 位。
- 第 0 位(0x01)表示 是否加密
- 其它位有压缩方式、UTF-8 文件名标记等
例如:
flag_bits = 0b0000000000000001 # 第0位为1,表示加密
而ZIP文件采用多段式结构,包含文件头、数据、目录等部分:
每个文件在ZIP中都有一个本地文件头,结构如下(偏移量从0开始):
偏移 大小 字段名 说明
0 4 local file header signature = 0x04034b50 (本地文件头签名)
4 2 version needed to extract 解压所需版本
6 2 flag_bits 通用目的比特标志
8 2 compression method 压缩方法
10 2 last mod file time 最后修改时间
12 2 last mod file date 最后修改日期
14 4 crc-32 CRC-32校验值
18 4 compressed size 压缩后大小
22 4 uncompressed size 压缩前大小
26 2 file name length 文件名长度
28 2 extra field length 额外字段长度
30 变长 file name 文件名
30+n 变长 extra field 额外字段
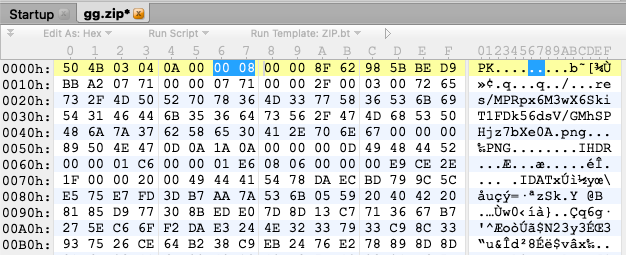
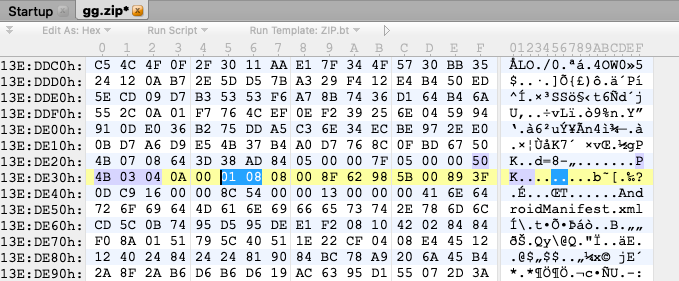
下图是zip包文件头,可以看到整个zip的flag_bits为0800,并未标记加密:
其他未标记加密的本地文件头flag_bits为0808
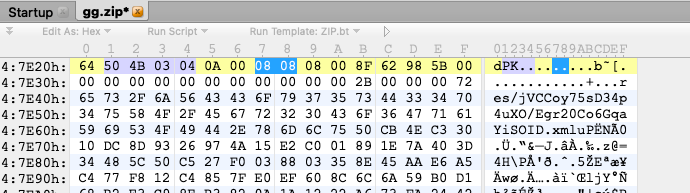
标记加密的本地文件头flag_bits为0801
偏移 大小 字段名 说明
0 4 central file header signature = 0x02014b50
4 2 version made by 创建ZIP的版本
6 2 version needed to extract 解压所需版本
8 2 **general purpose bit flag** **flag_bits字段**
10 2 compression method 压缩方法
12 2 last mod file time 最后修改时间
14 2 last mod file date 最后修改日期
16 4 crc-32 CRC-32校验值
20 4 compressed size 压缩后大小
24 4 uncompressed size 压缩前大小
28 2 file name length 文件名长度
30 2 extra field length 额外字段长度
32 2 file comment length 文件注释长度
34 2 disk number start 文件开始的磁盘号
36 2 internal file attributes 内部文件属性
38 4 external file attributes 外部文件属性
42 4 relative offset of local header 本地头相对偏移
46 变长 file name 文件名
... 变长 extra field 额外字段
... 变长 file comment 文件注释
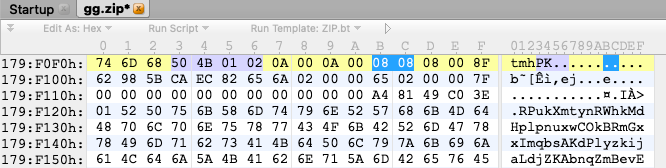
未标记加密的中央目录文件头flag_bits为0808
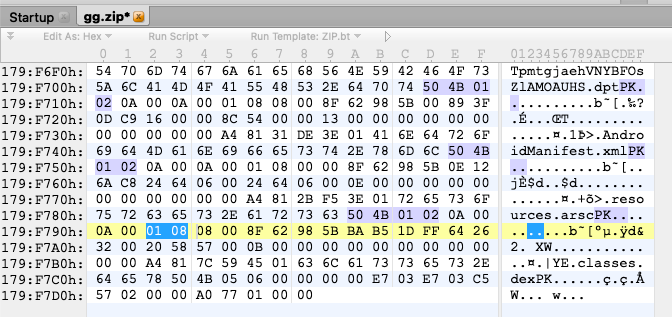
标记加密的中央目录文件头flag_bits为0801
0x33 flag_bits字段详解
位置:本地文件头偏移6字节处,2字节(16位)
同样存在于中央目录文件头中(偏移8字节处)
比特位 含义 说明
0 加密文件 1=文件已加密
1-2 压缩选项 1=最大压缩,2=最快压缩
3 数据描述符 1=存在数据描述符(重要的标志位)
4 强化的deflate 1=使用增强型deflate压缩
5 补丁数据 1=文件是补丁数据集
6 强加密 1=使用强加密(如DES)
7 未使用 保留位
8 未使用 保留位
9 文件名使用UTF-8编码 1=文件名使用UTF-8编码
10 加密中心目录 1=中央目录加密
11-15 未使用 保留位
0x4 解密脚本
根据上面的伪加密原理编写除去apk伪加密脚本如下
#!/usr/bin/env python3
"""
unfake_apk_crypto.py —— 一键去掉 APK 伪加密
用法:
python3 unfake_apk_crypto.py fake.apk [clean.apk]
如果省略第二个参数,则原地覆盖。
"""
import os
import sys
import zipfile
import shutil
def clean_pseudo_encryption(src_apk: str, dst_apk: str | None = None) -> str:
"""返回生成的新 apk 路径"""
if dst_apk is None or src_apk == dst_apk:
# 原地修改:先写到临时文件,最后再覆盖
tmp = src_apk + ".tmp"
clean_pseudo_encryption(src_apk, tmp)
shutil.move(tmp, src_apk)
return src_apk
with zipfile.ZipFile(src_apk, "r") as zin, \
zipfile.ZipFile(dst_apk, "w", compression=zipfile.ZIP_STORED) as zout:
for info in zin.infolist():
# 把加密标志位清 0
info.flag_bits &= ~0x01
# 按原数据写出
zout.writestr(info, zin.read(info.filename))
return dst_apk
if __name__ == "__main__":
if len(sys.argv) < 2:
print("用法: python3 unfake_apk_crypto.py <fake.apk> [clean.apk]")
sys.exit(1)
src = sys.argv[1]
dst = sys.argv[2] if len(sys.argv) > 2 else None
out = clean_pseudo_encryption(src, dst)
print(f"伪加密已去除 -> {out}")
其中&= ~0x01的含义如下:
- 0x01 是二进制:0000 0001
- ~0x01 是按位取反:1111 1110
- &= 是按位与赋值
所以:
info.flag_bits &= ~0x01
等价于:
info.flag_bits = info.flag_bits & 0b11111110
逻辑上:
- 把原来的 flag_bits 和 11111110 做 AND 运算
- 第 0 位会被强制置为 0,其他位保持不变
这样就把 加密 标志位清零了,而不影响其他标志位。
直接 info.flag_bits = 0 会把 所有标志位清零,可能会破坏 ZIP 条目的其他信息(比如 UTF-8 标记、压缩方式等)。
执行后apk文件已经被修改
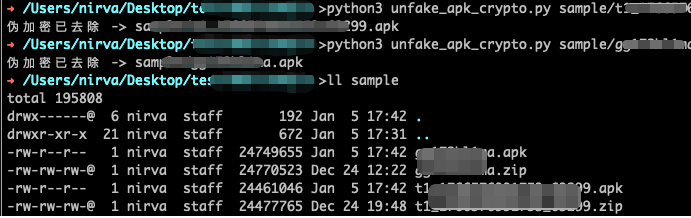
之后即可解压出文件内容:







